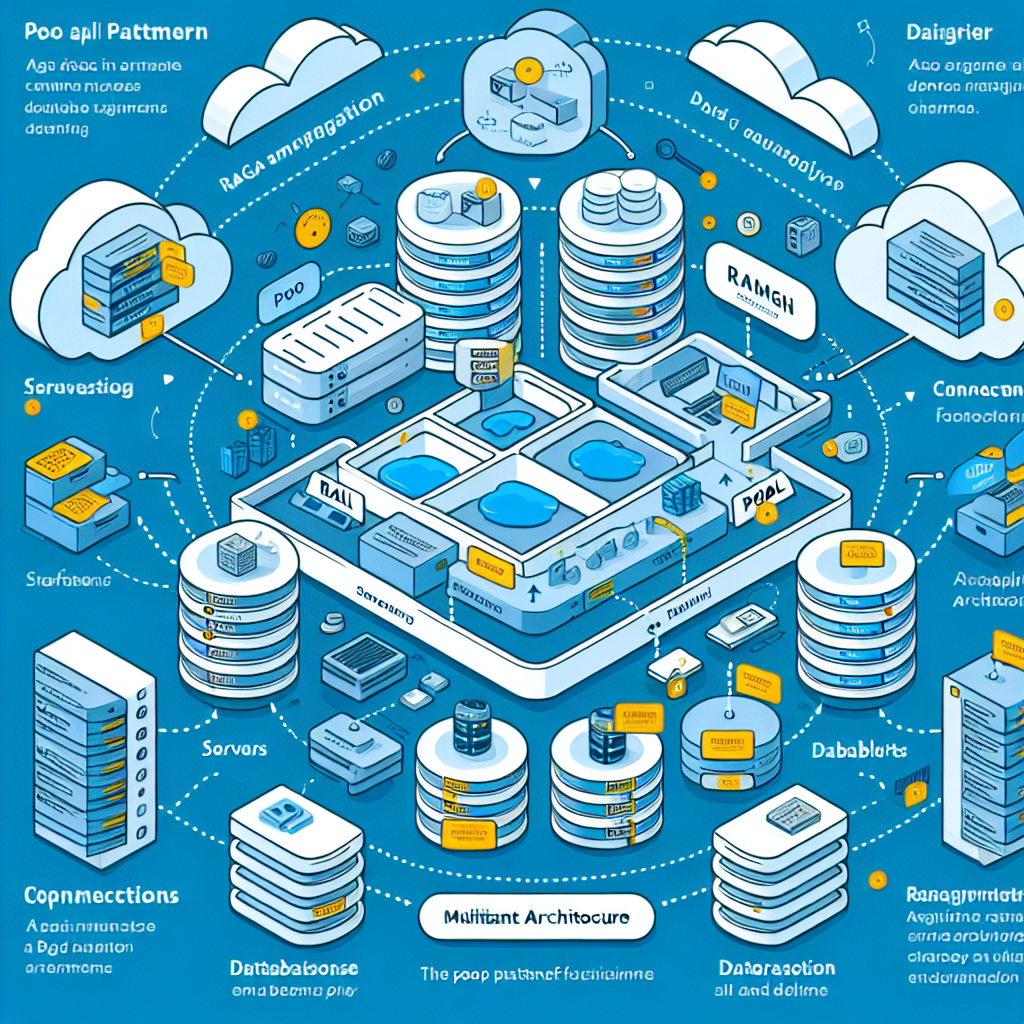
Introducción El patrón pool es un enfoque de infraestructura compartida en el que todos los inquilinos usan la misma base de conocimientos de Amazon Bedrock, el mismo bucket de S3 y la misma base de datos vectorial. En lugar de crear recursos independientes por cliente, se centralizan recursos y se mantiene la separación mediante metadatos aplicados en cada documento.
Concepto central En el patrón pool todos comparten un único bucket S3 para documentos, una única Knowledge Base para el procesamiento y una única base de datos vectorial como Pinecone o AWS OpenSearch. La separación entre clientes se logra exclusivamente mediante filtrado por metadatos que identifican userId y agentId.
Paso 1 Documentos y metadatos Al subir un documento se almacenan dos archivos relacionados en S3: el documento original y un archivo metadata.json asociado que contiene atributos como userId, username, agentId, nombre de archivo y fecha de subida. Este metadata.json es esencial para que el sistema pueda aislar la información de cada cliente dentro de la infraestructura compartida.
Paso 2 Ingesta en la Knowledge Base Todos los documentos se procesan con la misma Knowledge Base: se fragmentan siguiendo el mismo criterio de chunking, se generan incrustaciones con el mismo modelo de embeddings y se indexan en la base de datos vectorial junto con los metadatos. Gracias a esto se mantiene coherencia en la búsqueda semántica y en el almacenamiento de vectores.
Paso 3 Consultas con filtrado Cuando un usuario realiza una consulta, la búsqueda semántica aplica filtros en la base de datos vectorial usando los campos de metadatos como userId y agentId. Esto garantiza que el resultado devuelto pertenezca únicamente al inquilino y al agente autorizados, evitando que el Usuario A vea documentos del Usuario B.
Flujo visual simplificado 1 Subida de documento crea objeto S3 y metadata.json 2 Ingesta por la Knowledge Base procesa ambos archivos 3 Vectores almacenados en la base vectorial con userId y agentId 4 Consulta del usuario aplica filtro y solo devuelve documentos autorizados.
Detalles de implementación Agentes Cada usuario puede crear múltiples agentes con su propio nombre y descripción. Todos los agentes pueden referenciar la Knowledge Base compartida y el origen de datos común, pero las consultas y el contenido permanecen aislados por metadatos. Esto facilita la gestión de asistentes personalizados sin replicar infraestructuras.
Soporte multi modelo Aunque la Knowledge Base y el índice vectorial sean compartidos, cada sesión o agente puede seleccionar distintos modelos de IA para la generación de respuestas, por ejemplo Claude, Mistral, Titan o modelos de Amazon Bedrock, permitiendo flexibilidad en IA para empresas sin sacrificar eficiencia operativa.
Registro de usuarios y onboarding El onboarding es inmediato: al registrarse el usuario recibe permisos para usar la infraestructura compartida y se le aplican límites según su plan como número máximo de agentes, número máximo de documentos y mensajes mensuales. Esto simplifica la puesta en marcha y reduce el tiempo hasta valor para el cliente.
Ventajas Eficiencia de costes al centralizar la Knowledge Base para cientos de inquilinos, onboarding sencillo sin configuraciones por cliente, flexibilidad para elegir modelos de inteligencia artificial y seguridad basada en filtrado de metadatos que proporciona aislamiento efectivo entre clientes.
Factor crítico de éxito El archivo metadata.json es fundamental. Sin ese archivo los documentos no son filtrables por inquilino y la separación de datos queda comprometida. Es obligatorio garantizar que cada documento tenga su metadata.json con campos userId y agentId correctos para mantener la integridad del sistema multi tenant.
Consideraciones de seguridad y cumplimiento Implementar control de accesos, cifrado en reposo y en tránsito, auditoría de accesos y políticas de retención ayuda a reforzar la seguridad del patrón pool. Complementar con prácticas de ciberseguridad y monitoreo continuo reduce riesgos y mejora la confianza del cliente.
Aplicaciones reales Este enfoque es ideal para plataformas de agentes IA, gestor documental semántico y sistemas RAG multi tenant en los que se requieren respuestas personalizadas por cliente. Permite integrar servicios cloud aws y azure, soluciones de inteligencia de negocio y herramientas como power bi para enriquecer análisis y reporting.
Sobre Q2BSTUDIO Q2BSTUDIO es una empresa de desarrollo de software y aplicaciones a medida especializada en inteligencia artificial, ciberseguridad y servicios cloud aws y azure. Ofrecemos software a medida, aplicaciones a medida y servicios de inteligencia de negocio que incluyen implementaciones de ia para empresas, construcción de agentes IA y dashboards con power bi. Nuestra experiencia permite diseñar soluciones seguras y escalables que combinan desarrollo personalizado, integración de modelos de IA y mejores prácticas en ciberseguridad.
Palabras clave y posicionamiento aplicaciones a medida software a medida inteligencia artificial ciberseguridad servicios cloud aws y azure servicios inteligencia de negocio ia para empresas agentes IA power bi son parte integral de nuestras soluciones y del enfoque de Q2BSTUDIO para impulsar proyectos con alto valor diferencial.
Conclusión El patrón pool es una alternativa eficiente y escalable para RAG multi tenant cuando se diseña con metadatos rigurosos, controles de seguridad y buenas prácticas de ingesta y consulta. En Q2BSTUDIO podemos ayudar a implementar esta arquitectura, optimizar costes y asegurar aislamiento entre clientes mientras aprovechamos lo mejor de la inteligencia artificial y los servicios cloud.
