Introducción: En este artículo traduzco y adapto un enfoque práctico para construir un ETL ligero usando AWS Lambda, DuckDB y delta-rs para generar tablas en formato Delta Lake sobre S3. La idea central es descargar trabajo de preprocesado desde Databricks hacia funciones Lambda para reducir costes y mantener Databricks para las capas Silver y Gold donde se requiere mayor potencia de cómputo.
Qué es Delta Lake: Delta Lake es un formato de lago de datos compatible con ACID construido sobre Parquet. Sus capacidades clave incluyen transacciones ACID para mantener consistencia con escrituras concurrentes, time travel para consultar versiones históricas, evolución de esquema y optimizaciones de rendimiento. Es el formato principal en Databricks y muy usado para pipelines de ETL, BI y machine learning.
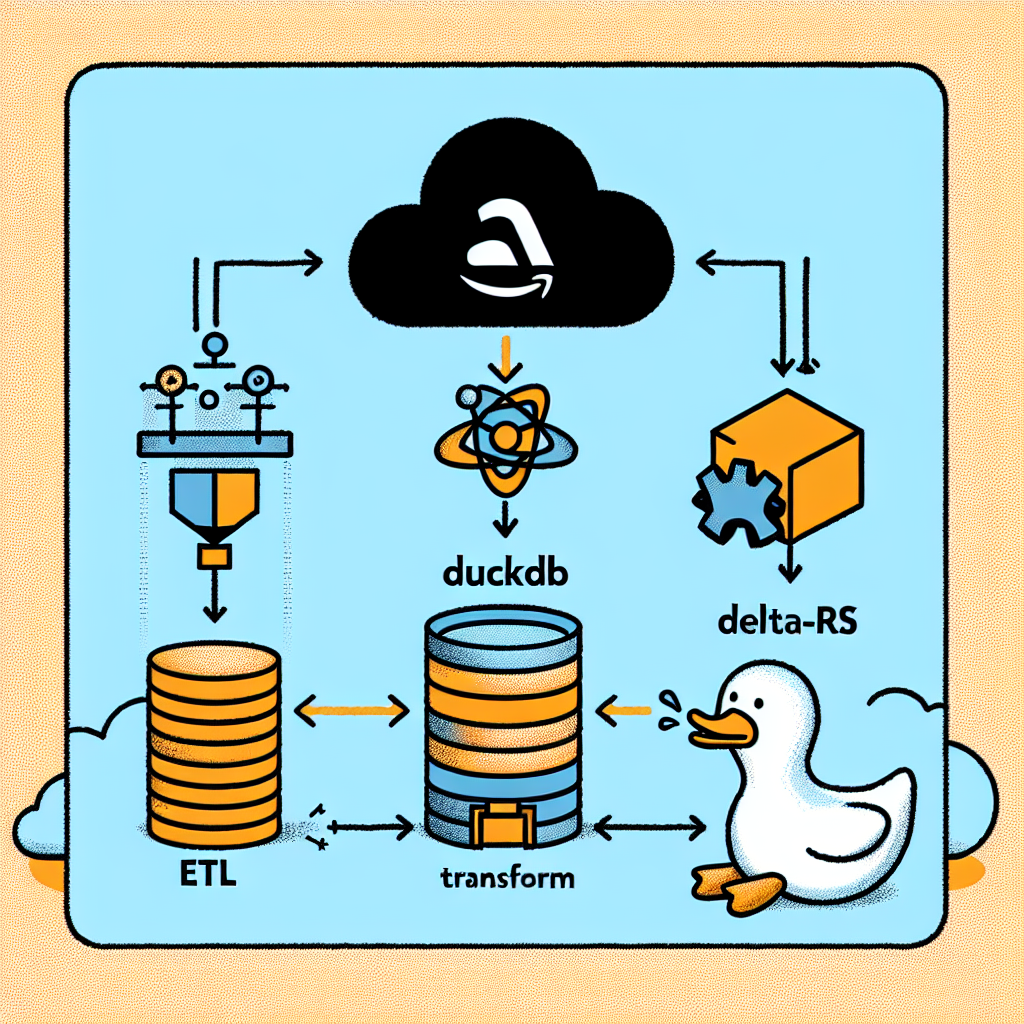
Arquitectura propuesta: El flujo propuesto separa responsabilidades por capas. La capa Landing a Bronze se encarga con Lambda y produce datos en formato Delta sobre S3. Las capas Bronze a Silver y Silver a Gold se ejecutan en Databricks para transformaciones pesadas, agregados y preparación final para BI o modelos ML. Las librerías utilizadas dentro de Lambda son DuckDB para consultas SQL en memoria, PyArrow para manejo eficiente de tablas columnares y delta-rs para leer y escribir tablas Delta.
DuckDB: DuckDB es un motor OLAP embebido y ligero, ideal para Lambda por su capacidad de procesar en memoria y ejecutar consultas analíticas y transformaciones por lotes de forma rápida, con sintaxis SQL similar a PostgreSQL.
PyArrow: PyArrow es la implementación Python de Apache Arrow que proporciona un formato de memoria columnar de alta velocidad. Facilita conversiones eficientes entre estructuras y una interoperabilidad ágil entre DuckDB, delta-rs y otras herramientas analíticas.
delta-rs: delta-rs es una implementación en Rust de Delta Lake con enlaces para Python bajo el paquete deltalake. Permite operaciones ACID, evolución de esquema y time travel desde entornos fuera de Databricks, por ejemplo en funciones Lambda o contenedores ligeros.
Preparación de Databricks y S3: Integrar Databricks con S3 normalmente implica crear una External Location y ejecutar el CloudFormation que configura permisos y roles para acceso seguro desde Databricks a los buckets. Una vez hecho esto se pueden gestionar catálogos y tablas con SQL desde la interfaz de Databricks.
Empaquetado para Lambda: Dado que las dependencias como DuckDB, PyArrow y deltalake pueden ser pesadas, se recomienda construir una imagen de contenedor basada en la imagen oficial de Lambda para Python y preinstalar las librerías necesarias. Esto simplifica despliegues y evita límites de tamaño en paquetes ZIP.
Requisitos típicos: Incluir en el contenedor las librerías duckdb, pyarrow y deltalake en versiones compatibles para asegurar escritura hacia Delta Lake desde Python.
Ejemplo de flujo dentro de Lambda: La función conecta a DuckDB en memoria, carga datos de un archivo Parquet desde S3 mediante read_parquet, ejecuta la lógica SQL de filtrado o limpieza, recupera el resultado como tabla Arrow, ajusta tipos como timestamps para evitar incompatibilidades y finalmente escribe el resultado en una tabla Delta sobre S3 usando deltalake. Este patrón permite realizar un preprocesado eficiente y almacenar resultados en formato Open Table Format listo para consumo por Databricks.
Nota importante sobre timestamps y WriterVersion: Si una tabla Delta tiene WriterVersion mayor o igual a 7 y contiene timestamps sin zona horaria puede aparecer el error que indica que se debe especificar la feature TimestampWithoutTimezone. La solución práctica es convertir columnas timestamp con resolución en microsegundos a timestamp en nanosegundos con zona UTC antes de escribir. También se recomienda usar versiones de deltalake iguales o superiores a 1.1.4 para compatibilidad con estas features.
Ejemplo de caso de uso y despliegue: Un ejemplo real es procesar archivos de muestra como el conjunto NYC Taxi desde S3. Un trigger de S3 invoca Lambda por cada nuevo objeto, Lambda ejecuta las transformaciones ligeras con DuckDB y PyArrow y escribe en Delta Lake. Databricks luego consume la capa Bronze para efectuar joins, normalización, validaciones de calidad y agregados en las capas Silver y Gold.
Responsabilidades por capa: Landing a Bronze con Lambda, DuckDB y delta-rs para ETL ligero y coste eficiente. Bronze a Silver en Databricks para transformaciones pesadas, modelado y enriquecimiento. Silver a Gold en Databricks para métricas de negocio, data marts y conjuntos listos para BI y ML.
Ventajas del enfoque: Menor coste al evitar jobs pesados solo para preprocesado, despliegue rápido usando Lambda y contenedores, uso de SQL para lógica ETL, procesamiento en memoria eficiente con DuckDB y capacidad de ingestión casi en tiempo real con triggers de S3.
Límites y consideraciones: Lambda tiene límite de memoria y tiempo de ejecución (hasta 10 GB y 15 minutos respectivamente) por lo que para datasets muy grandes o ventanas de procesamiento continuas puede ser necesario optar por ECS, Fargate o instancias spot para escalado horizontal.
Conclusión técnica: Usar AWS Lambda más DuckDB y delta-rs es una alternativa práctica y económica para construir la capa Bronze en pipelines modernos que usan Delta Lake. Tras el preprocesado, Databricks puede encargarse de los trabajos de limpieza avanzada, modelado y explotación analítica, permitiendo una arquitectura híbrida eficiente.
Sobre Q2BSTUDIO: Q2BSTUDIO es una empresa de desarrollo de software especializada en aplicaciones a medida y software a medida. Ofrecemos servicios completos que incluyen inteligencia artificial para empresas, agentes IA, servicios de ciberseguridad, servicios cloud AWS y Azure y soluciones de inteligencia de negocio. Nuestra experiencia abarca desde la integración de pipelines de datos y ETL ligeros hasta el desarrollo de modelos de IA, dashboards con Power BI y arquitecturas seguras en la nube.
Cómo Q2BSTUDIO puede ayudar: Podemos diseñar e implementar pipelines que combinen Lambda, DuckDB y delta-rs para reducir costes operativos, preparar datasets listos para Databricks y automatizar flujos para BI y ML. Implementamos soluciones de IA para empresas, agentes conversacionales basados en IA, análisis avanzado con Power BI y estrategias de ciberseguridad para proteger sus activos digitales.
Palabras clave y servicios: aplicaciones a medida, software a medida, inteligencia artificial, ciberseguridad, servicios cloud aws y azure, servicios inteligencia de negocio, ia para empresas, agentes IA, power bi. Si buscas optimizar costes en ingestión y preprocesado o quieres una arquitectura escalable para analítica y ML, Q2BSTUDIO puede diseñar la solución adecuada a tus necesidades.
Contacto y siguiente paso: Si te interesa una prueba de concepto para implementar ETL ligero hacia Delta Lake o integrar Databricks con un flujo eficiente y seguro, contacta con Q2BSTUDIO para que evaluemos tus requisitos y propongamos una solución a medida.

.jpg)
.jpg)